 I applied some of the many techniques that we covered in Gilad Lotan’s Social Data Analysis class to the Free Music Archive, a curated resource for free legal mp3 downloads. I directed the FMA before coming to ITP, so I already had some hunches about what I might find. But I had primarily dealt with its database through a CMS, and I was excited to explore using new tools. My goal was to uncover data that could help users discover music, connect users with similar taste, chart trends and make sense of the FMA’s user community.
I applied some of the many techniques that we covered in Gilad Lotan’s Social Data Analysis class to the Free Music Archive, a curated resource for free legal mp3 downloads. I directed the FMA before coming to ITP, so I already had some hunches about what I might find. But I had primarily dealt with its database through a CMS, and I was excited to explore using new tools. My goal was to uncover data that could help users discover music, connect users with similar taste, chart trends and make sense of the FMA’s user community.
Using custom MySQL queries, I worked with timestamped tables for Track Favorites, Track Downloads and Track Listens, as well as tables for Genres, Friendships (between users), Users, and Tracks.
My first hunch was that only a very small percentage of users sign up for accounts, since you don’t need to register in order to download. I found that of 58,012,839 total track downloads, only 401,380 ( 0.69 %) were associated with a logged in user ID. I decided to limit my Track Downloads data to logged in users, because a table of 58 million was hard to work with.
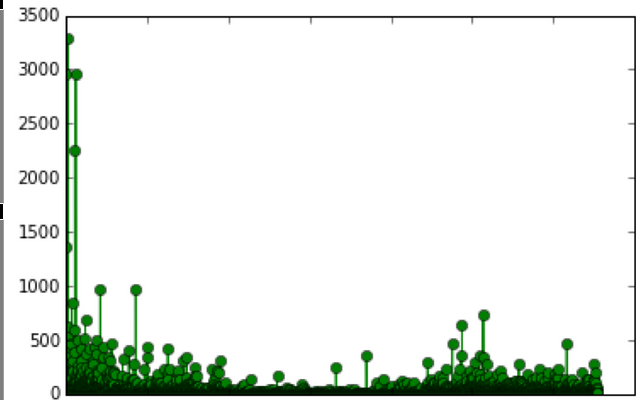
My second hunch was that, of the registered users, a much smaller group of them is the most influential, active, and inter-connected, and it might be useful to highlight the recommendations of these more active users. I found found that 37,140 registered users have downloaded a track, 21,664 users have favorited a track, but only 1,303 have created a playlist. For each of these metrics, there are a few very active users, and a long tail of users who are less active. For example, here’s what the graph looks like mapping user ID to number of favorites:
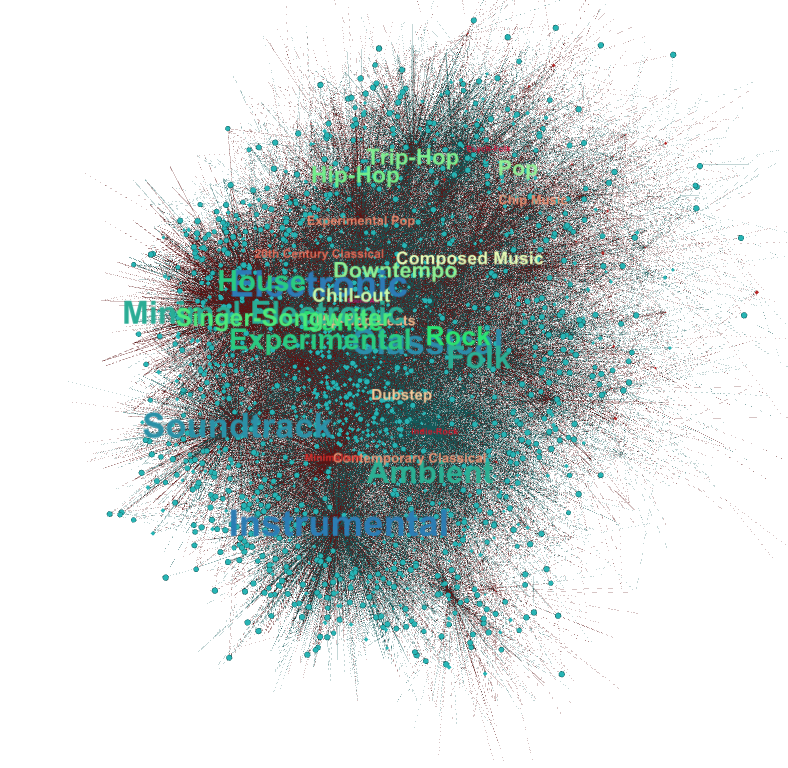
I wanted to get a better sense of the user community of the FMA with a network graph. I created a graph using NetworkX in Python, where every user who has favorited a track gets a node, and edges are drawn between users who have common favorites, as well as users who friend each other. I plotted the graph using different layout algorithms in Gephi. At first, I found it difficult to isolate modularity and find communities within the FMA userbase beyond one central group and a bunch of relatively quieter outsiders.


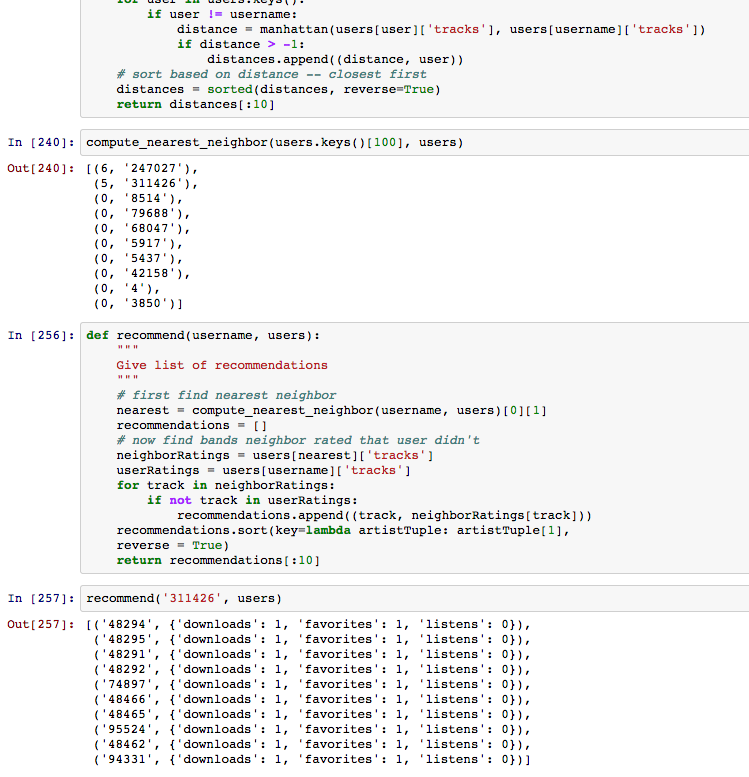
My hunch is that users can provide a great pathway to music discovery. But most users don’t participate in the social aspect of the site by friending their fellow users, and it’s hard to find users since there is no user search functionality. So I made a recommendation method that suggests users based on favorites, listens and downloads. I used Manhattan Distance and Nearest Neighbor Algorithm so that users’ tastes do not need to overlap directly. I don’t have great visuals to show for this, and I’d need to keep working on it before it could offer really good recommendations for tracks and/or users, but I think it would be a useful thing to bring to the site. It could recommend both tracks and users based.
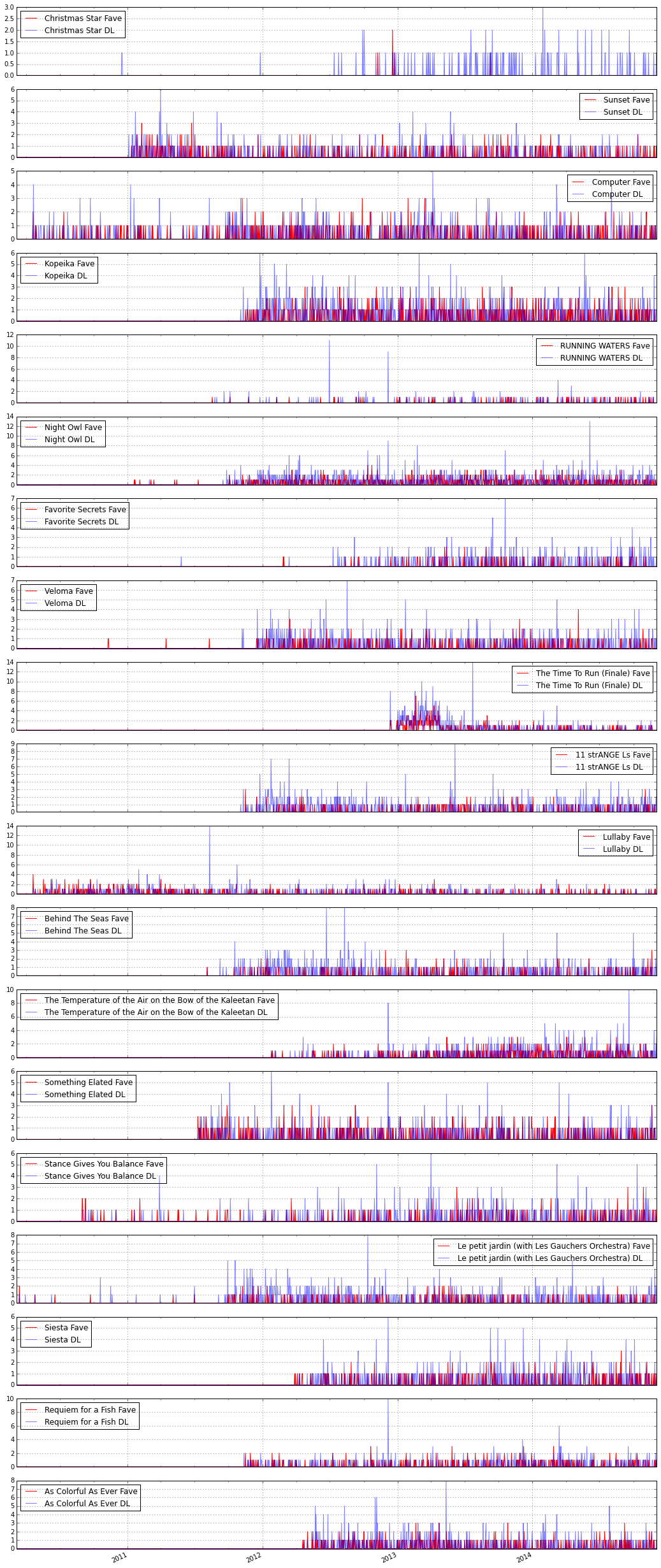
Next, I wanted to see how tracks achieve popularity on the site. Is there a correlation between favorites and downloads? I compared time series data for favorites and downloads (by registered users only) for the 10 most favorited and 10 most downloaded tracks. Click to expand these:
Brian Clifton suggested I use Rolling Mean to get a smoother plot of the data:
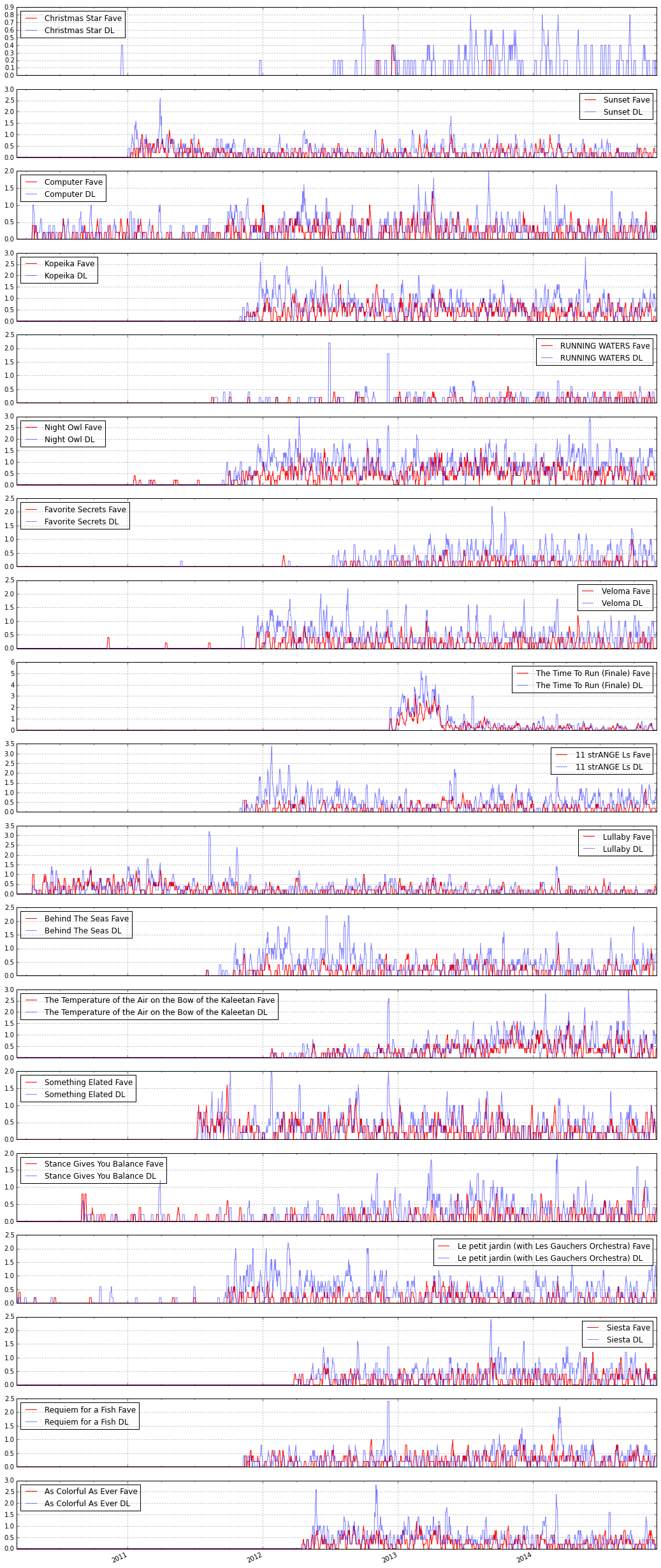
I was surprised to find relatively steady trends here—some tracks are consistently popular. On the other hand, some seem to take a while before becoming popular. Others are downloaded frequently, but not favorited, like the Christmas song—why is that? During class presentations, it was suggested that I dig deeper into this Time Series data to find if the users who favorite are also the users who download.
Looking at the time series data for all favorites, I found that there were big spikes in favorite-ings on certain days:
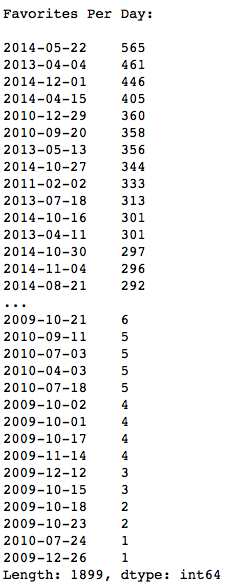
I wanted to see if these days meant that a specific track had debuted on the site—perhaps on the front page—or if a user suddenly became very active in exploring and favoriting. I found that, in many cases, days with many favoritings like May 22 2014 were when a new user registered for the site and started to favorite a bunch of tracks.
When certain users favorite a track, does that lead it to become popular? I tried to calculate the influence of certain users based on when they favorited tracks that would go on to become popular. My first approach involved calculating the “deltaTime” in seconds between when they favorited the track and when it was first published, and factoring in the amount of total favorites. Later I found a more useful method of assigning influence to a user would be to weight every user who favorited a track after the user’s favoriting occurred. I used the time series data for the 1000 most popular tracks, and calculated the influence of every user who had favorited those tracks.
I further differentiated each user by giving each user a dictionary of genres, and this way every user could have a global influence, as well as a genre-specific influence.
This resulted in a very different graph of users than my initial graph, and it highlights different users who I had never come across before.

I would like to continue exploring methods to spotlight users who are influential within particular genres, so that when FMA visitors browse by genre, they could be recommended users to follow. The “browse by genre” results could also spotlight tracks that are popular among the most influential users / tastemakers within that genre.
Finally, I made a bipartite version of this graph, with edges between users and genres based on how many tracks they have favorited within that genre.
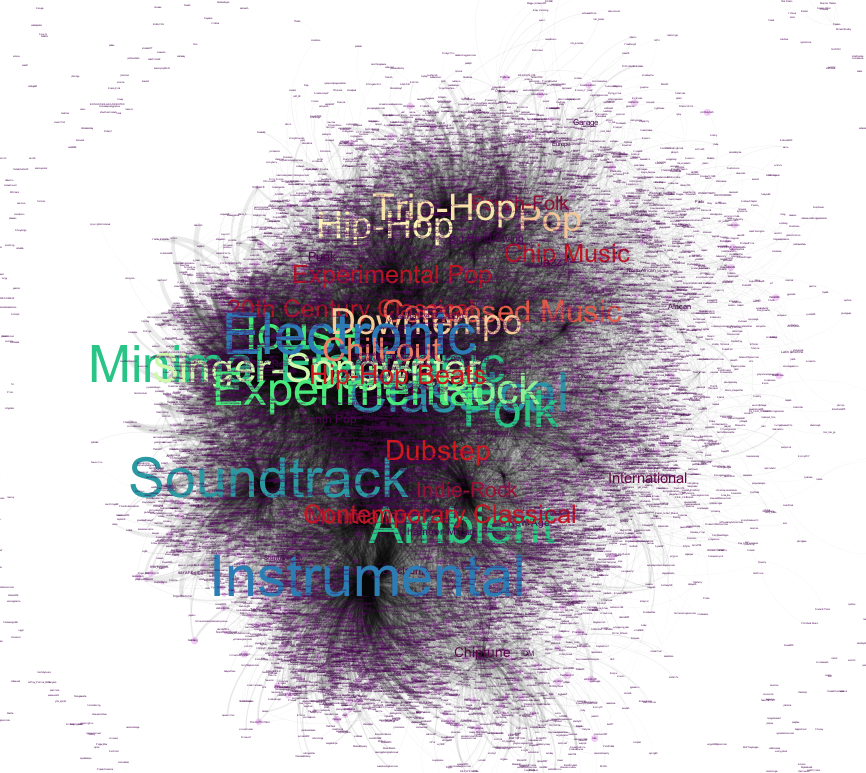
Lots more to dig into, but never enough time.